The reason some U.S. AI startups use Chinese models
Open models are cheap to run and can be optimized by developers

TL;DR
AI startups are building on top of open-source Chinese models.
Open-source eliminates platform risk.
Founders don’t want to be constrained by platform incentives or political edicts from Washington, DC.
Open models offer cheaper inference and allow full visibility into model weights.
U.S. export controls on cutting-edge GPUs accelerate the rise of a global open-weights system driven by Chinese AI researchers.
Algorithmic efficiency, not access to H100s, becomes the real bottleneck
The dirty secret in Silicon Valley is that some1 AI startups are not building on top of OpenAI or Anthropic. Rather, they’re using Chinese open source models.
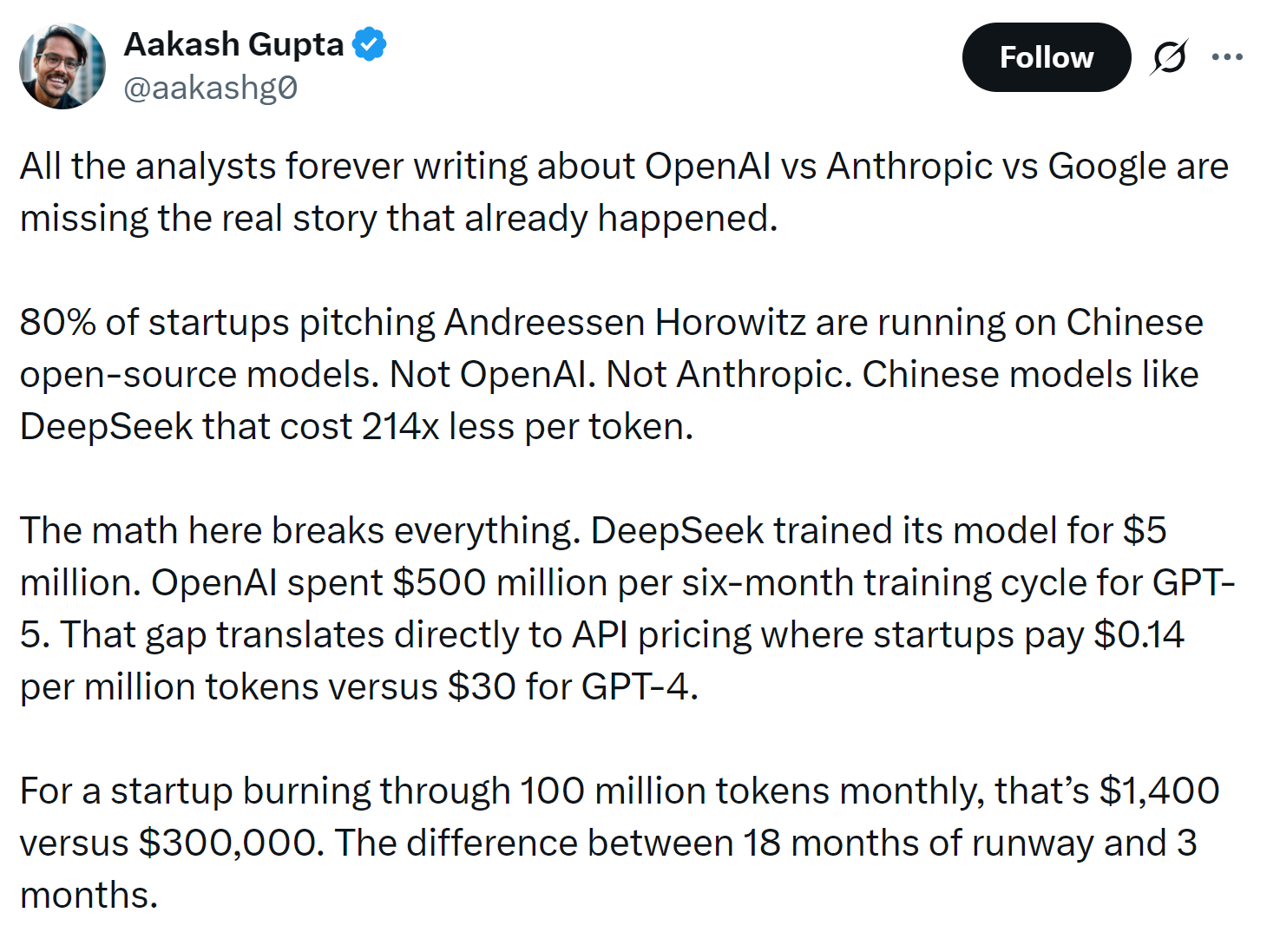
The surface observation, which Aakash notes in the screenshot captured above, is that open source is cheap and transparent. That’s true, but it’s not the strongest explanation for why Silicon Valley-based founders are building on top of DeepSeek-style Chinese models2.
The deeper interpretation goes something like this: The decision isn’t about Chinese models. It’s about de-risking platform dependency.
Building on OpenAI/Anthropic/Google introduces lethal platform risk: if your product is just a thin wrapper over an API, the platform can, and eventually will, either (a) clone it, or (b) kill its economics by changing pricing or rate limits. The fear is not imaginary; it has precedent across every API-dependent ecosystem. Just ask all the app developers whose apps have been sherlocked by Apple.
Developers ask themselves: Why would I build on top of a predator?
Chinese open source models solve four key business risks for founders:
Cost risk: inference is cheaper and getting cheaper faster, especially when tuned for specific tasks.
Weight visibility: Open source models allow developers to inspect, prune, quantize, and fine-tune internal representations. This helps developers optimize the models for whatever they’re building on top.
Governance risk: U.S. LLM vendors are increasingly political gatekeepers. Startups don’t want to depend on unpredictable ToS based on Washington’s political prerogatives. As the national security state permeates the institutional AI system, this becomes an exigent and existential risk.
Strategic foreclosure risk: If you succeed, OpenAI can absorb your feature into its platform and annihilate you.
The real draw, then, is not “Chinese”. It’s open, modifiable, and commercially safe. DeepSeek could have been Swiss, Indian, Brazilian, whatever. If it’s open, fast, cheap, and permissive, it wins early-stage adoption.
The unbundling of frontier models into specialized, sovereign stacks
For many applications, founders are discovering that:
a smaller, domain-tuned model beats a frontier model in cost-adjusted output
toolformer + RAG often matters more than raw model capabilities
you can run it on your own hardware (GPUs, H100 rentals, edge devices, etc.)
So the production function shifts from AI = call someone else’s API to AI = own weights + tuned inference + proprietary data integration . This is the same pattern that killed Heroku, Facebook platform apps like Zynga, and many AWS Lambda-driven startups: the platform eats the margins.
The contrarian observation
If A16Z portfolio companies are disproportionately choosing Chinese open models, it suggests:
U.S. export controls are leaking influence to PRC open model ecosystems.
The market values compute efficiency and permissive licenses more than Washington expected.
AI industrial policy may accidentially subsidize a global open-weights movement that routes around U.S. control.
There is a geopolitical implication: LLM capability is not bottlenecked solely by GPU access anymore. It’s bottlenecked by algorithic efficiency and distributed fine-tuning competence.
Conclusion
Incentives, as Munger is said to have averred, drive outcomes. When the U.S. restricts export of its cutting-edge chips to China, resourceful Chinese AI researchers optimize the software. When U.S. LLM vendors introduce restrictive licensing terms and operate at the behest of Washington, DC, startup founders route around those restrictions and choose open models, many of which, of course, happen to be Chinese.
Unintended consequences, non-linear systems: exactly the type of feedback loops that national security-adjacent Washington, DC lawyers don’t model well.
If you enjoy this newsletter, consider sharing it with a colleague.
I’m always happy to receive comments, questions, and pushback. If you want to connect with me directly, you can:
follow me on Twitter,
connect with me on LinkedIn, or
send an email to dave [at] davefriedman dot co. (Not .com!)
Edit Nov 18th 2025: I changed this from most to some. See Martin Casado’s tweet on the topic. I think the rest of the post holds in spite of the edit.
On the claim that DeepSeek cost only $5 million: this is controversial, and there is nuance to be had. Stratechery noted that “DeepSeek is clear that these costs [of around $5 million] are only for the final training run, and exclude all other expenses.” Stratechery links to DeepSeek’s paper, and quotes the salient part, which I’ve excerpted:
Assuming the rental price of the H800 GPU is $2 per GPU hour, our total training costs amount to only $5.576M. Note that the aforementioned costs include only the official training of DeepSeek-V3, excluding the costs associated with prior research…”
(emphasis is mine).
Thanks for sharing! Do you think that American LLMs will ever become as efficient as Chinese models considering we are scaling with compute while they are capacity-constrained?
Should not using open ai and hyperscalers platforms for the reasons mentioned be beneficial for neoclouds like NBIS?