

Will AI companies have to cough up cash for training data?
Getty Images sues Stability AI and people are panicking about higher data acquisition costs

Getty Images alleges that Stability AI “unlawfully copied and processed millions of images protected by copyright and the associated metadate owned or represented by Getty Images absent a license to benefit Stability AI’s commercial interests and to the deteriment of the content creators.” Getty further states:
Getty Images believes artificial intelligence has the potential to stimular creative endeavors. Accordingly Getty Images provided licenses to leading technology innovators for purposes related to training artificial intelligence systems in a manner that respects personal and intellectual property rights. Stability AI did not seek any such license from Getty Images and instead, we believe, chose to ignore viable licensing options and long-standing legal protections in pursuit of their stand-alone commercial interests.
In short, Getty Images alleges that Stability AI illegally used Getty Images’ data. One of Getty Images’ complaints is that Stability AI’s output includes Getty Images’ watermark in some of its generated images. Getty Images is understandably upset at this, as it implies a relationship between Getty Images and Stability AI. Getty’s press release makes it pretty clear that such a relationship doesn’t exist. Thus, its lawsuit.
An article in The Verge notes:
The lawsuit marks an escalation in the developing legal battle between AI firms and content creators for credit, profit, and the future direction of the creative industries. AI art tools like Stable Diffusion rely on human-created images for training data, which companies scrape from the web, often without their creators’ knowledge or consent. AI firms claim this practice is covered by laws like the US fair use doctrine, but many rights holders disagree and say it constitutes copyright violation. Legal experts are divided on the issue but agree that such questions will have to be decided for certain in the courts. (This past weekend, a trio of artists launched the first major lawsuit against AI firms, including Stability AI itself.)
Here’s an example of one of the faux-watermarked images that Getty Images objects to:

Aside from the hallucinatory nature of the image—note the quarterback’s anatomically bizarre arm and the guy on the left crouching as if he were a baseball catcher—it apparently has the imprimatur of Getty Images. Except, of course, we know that it doesn’t. But, to Getty’s point, the casual viewer likely has no clue.
One argument I’ve seen bruited about in light of this lawsuit is the claim that, should Getty Images prevail over Stability AI, companies which train large language models (LLMs) will be forced to pay a lot of money for all the data that they require. I don’t think that’s true. And I don’t think it’s true for one very important reason: synthetic data.
Here’s Wiki’s explanation of synthetic data:
Synthetic data is increasingly being used for machine learning applications: a model is trained on a synthetically generated dataset with the intention of transfer learning to real data. Efforts have been made to construct general-purpose synthetic data generators to enable data science experiments.[12] In general, synthetic data has several natural advantages:
once the synthetic environment is ready, it is fast and cheap to produce as much data as needed;
synthetic data can have perfectly accurate labels, including labeling that may be very expensive or impossible to obtain by hand;
the synthetic environment can be modified to improve the model and training;
synthetic data can be used as a substitute for certain real data segments that contain, e.g., sensitive information.
This usage of synthetic data has been proposed for computer vision applications, in particular object detection, where the synthetic environment is a 3D model of the object,[13] and learning to navigate environments by visual information.
At the same time, transfer learning remains a nontrivial problem, and synthetic data has not become ubiquitous yet. Research results indicate that adding a small amount of real data significantly improves transfer learning with synthetic data. Advances in generative adversarial networks (GAN), lead to the natural idea that one can produce data and then use it for training. This fully synthetic approach has not yet materialized,[14] although GANs and adversarial training in general are already successfully used to improve synthetic data generation.[15]
Currently, synthetic data is used in practice for emulated environments for training self-driving cars (in particular, using realistic computer games for synthetic environments[16]), point tracking,[17] and retail applications,[18] with techniques such as domain randomizations for transfer learning.[19]
Synthetic data is data that is created in a simulation, by a computer. Unlike real-world data (and Getty Images’ data is based on real-world data, even though Getty Images’ images are stored digitally), synthetic data is instantiated in, and exists entirely in, silicion. It is in silico.
So why is synthetic data so important here? It has nothing to do with Getty Images’ lawsuit. But it is important because, even if Getty Images prevails in its lawsuit, companies that have a lot of data to sell won’t be able to suddenly extract onerous licensing terms from Stability AI or its competitors. I expect that future LLMs will be mainly trained on synthetic data.
Here is NVIDIA discussing synthetic data:
Synthetic data is annotated information that computer simulations or algorithms generate as an alternative to real-world data.
Put another way, synthetic data is created in digital worlds rather than collected from or measured in the real world.
It may be artificial, but synthetic data reflects real-world data, mathematically or statistically. Research demonstrates it can be as good or even better for training an AI model than data based on actual objects, events or people.
Now, it may reasonably be argued here that NVIDIA is talking its book. If the future of LLM training is synthetic data, then NVIDIA will sell more GPUs to create and analyze that data. NVIDIA even provides this handy graph:
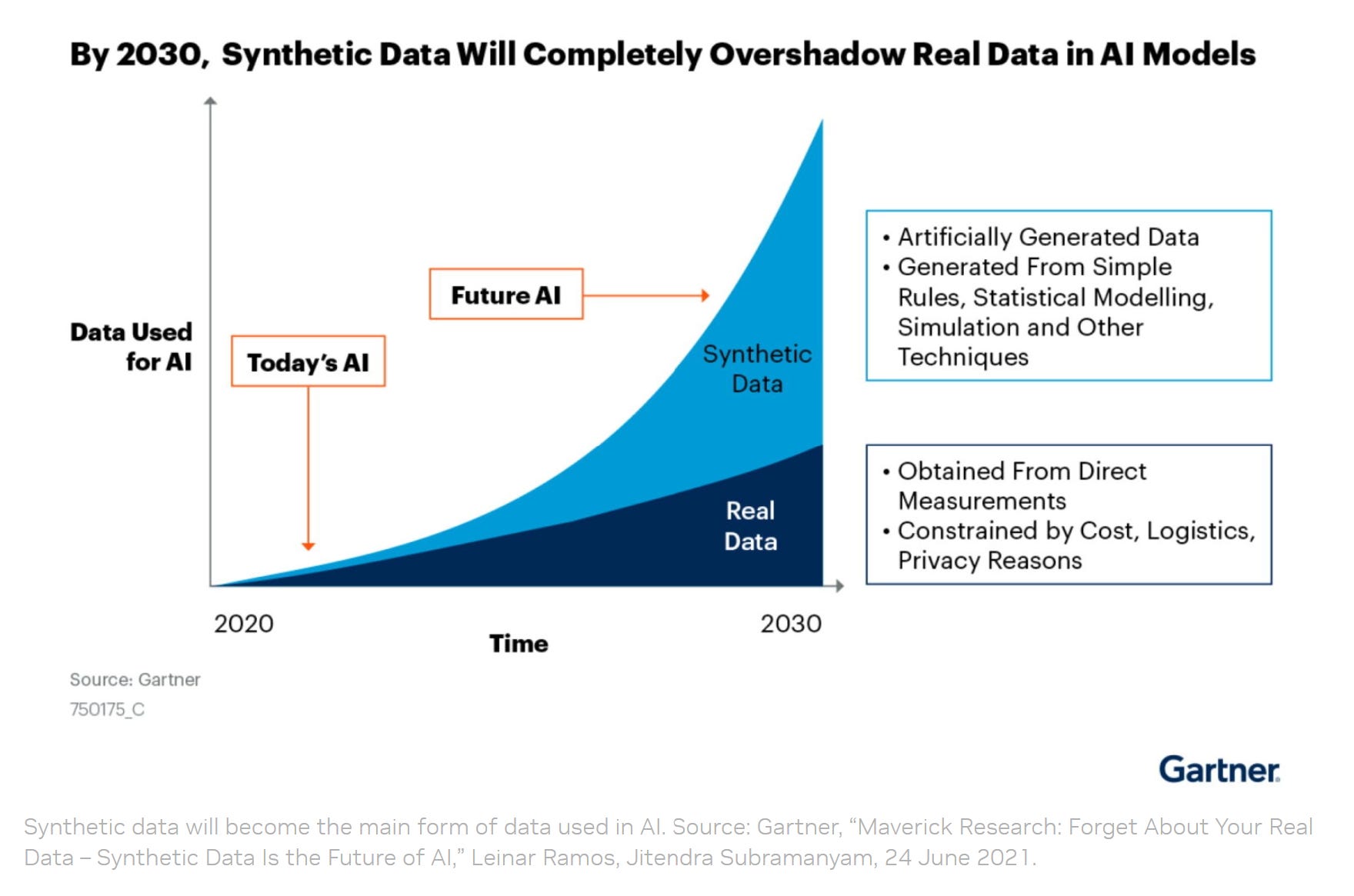
NVIDIA continues with its explanation:
A single image that could cost $6 from a labeling service can be artificially generated for six cents, estimates Paul Walborsky, who co-founded one of the first dedicated synthetic data services.
Cost savings are just the start. Synthetic data can address privacy issues and reduce bias by ensuring users have the data diversity to represent the real world.
Because synthetic datasets are automatically labeled and can deliberately include rare but crucial corner cases, it’s sometimes better than real-world data. For example, in the video below NVIDIA Omniverse Replicator generates synthetic data to train autonomous vehicles to navigate safely amid shopping carts and pedestrians in a simulated parking lot.
So: either the companies which assemble and train LLMs will have to buy expensive data on which to train these LLMs, or they will create synthetic data more cheaply (using NVIDIA’s GPUs, of course). It seems more likely to me that these companies will avail themselves of synthetic data, given that it is (1) cheaper to acquire than non-synthetic data and (2) the research into synthetic data shows that it is as effective for training LLMs as non-synthetic data.
Therefore, irrespective of how Getty fares in its lawsuit against Stability AI, I don’t think it’s the case that companies with data to sell will see a windfall if Getty prevails over Stability AI. The future is synthetic.