The GPU Risk No One is Managing
The exposures, the hedges that don't exist yet, and what to do about it

Editor’s note: the interactive model that appears in this post is throwing some errors; I will fix them soon.
TL;DR
GPUs are wasting assets, not normal capital equipment.
Four distinct risks: (1) low utilization; (2) future replacement costs; (3) residual value; (4) market compute prices diverge from your internal costs.
Short volatility on semiconductor prices: price spikes hurt refresh budgets; price crashes hurt your residual values; utilization variance hurts because your prices are fixed.
The obvious hedges don’t exist yet: Basis risk is severe. H100s aren’t fungible commodities like crude oil. Most early hedging will be commercial terms negotiated by procurement, not financial derivatives executed by treasury.
Tech companies hold $100B+ in GPU assets with less risk management than they’d apply to currency exposure.
Your company just filed its 10-K. Somewhere in the footnotes under “Property, Plant & Equipment” is a line item: $50 million in GPU infrastructure, depreciating over five years at 20% annually. Your auditors signed off. Your CFO presented it to the board. The investment makes strategic sense—you need compute capacity to compete in AI.
Here’s what’s less obvious: those GPUs represent one of the most poorly-instrumented exposures in your risk portfolio. They’re not depreciating like a building or machinery. They’re technology assets in a market where the next generation doesn’t just improve on the last one—it can make it economically obsolete within 18-36 months.
And unlike other major financial exposures your company routinely manages—currency fluctuations, interest rate movements, commodity price swings—most companies aren’t actively managing GPU risk. Not because CFOs lack sophistication, but because the measurement apparatus is missing, the market infrastructure is nascent, and the frameworks for quantifying these exposures are still developing.
The scale is getting significant. Tech companies plausibly hold $100+ billion in GPU assets—a back-of-envelope estimate based on hyperscaler CapEx guidance (Meta alone allocated $60-65 billion for AI infrastructure in 2025) plus mid-tier AI companies carrying $500 million to $2 billion in GPU clusters.
This raises important questions: What happens when next-generation GPUs launch and residual values decline faster than your depreciation schedule? What happens when your refresh cycle arrives but procurement costs have spiked? What happens when your utilization falls short of projections and your fixed costs become uneconomical?
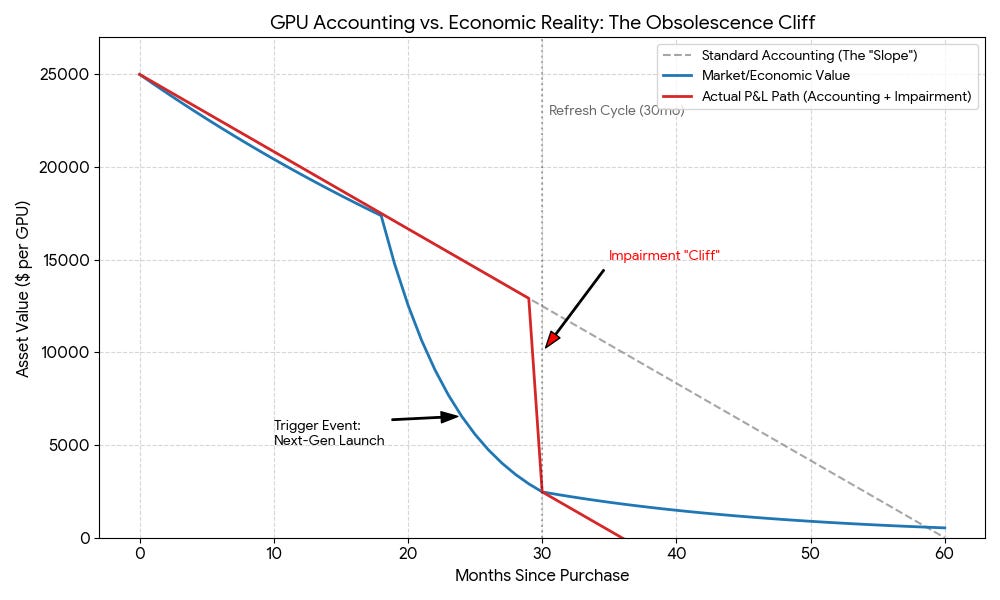
The accounting will show smooth depreciation punctuated by occasional impairments—cliffs, not slopes. The underlying economics might be more volatile. Understanding that gap is becoming an essential question for CFOs and risk managers.
The Four Exposures Worth Understanding
When you own a GPU cluster, you’re not just holding depreciating capital equipment. You’re taking four distinct positions that are worth examining:
Exposure #1: Utilization variance (The one that dominates everything else)
Most “GPU risk” is actually demand risk for your own workloads masquerading as hardware risk. A GPU cluster is a leveraged bet on a single variable: realized useful work per dollar of CapEx.
At 90% utilization generating $4/GPU-hour in internal value, your economics look excellent. At 50% utilization, you’re suddenly generating half the value while absorbing the same fixed costs. The GPUs haven’t changed—your ability to use them productively has.
This exposure is harder to hedge through financial instruments because it’s idiosyncratic to your business. The tools are operational: leasing instead of owning, maintaining workload portability, splitting your fleet into “core” capacity plus “surge” capacity from cloud providers, structuring offtake agreements that give you flexibility.
But utilization variance changes how you think about every other exposure. Low utilization transforms “residual value doesn’t matter” into “residual value is our exit strategy.” It’s the uncertainty that makes hardware risk material instead of theoretical.
Exposure #2: Future replacement cost
At some point—18 months, 36 months, whenever your refresh cycle arrives—you’ll need to procure next-generation capacity. The question is: what will that cost?
If next-gen GPUs deliver equivalent performance for $20,000 per unit, your economics improve. If supply constraints, manufacturing bottlenecks, or vendor pricing push them to $40,000, your refresh budget could double. On a 1,000-GPU refresh, that’s a $20 million variance with no protection.
You’re effectively short volatility on future procurement costs. A price spike hurts asymmetrically—you need the capacity regardless of what it costs.
Airlines face analogous exposure with jet fuel, which is why they often hedge forward fuel costs using call options or caps. The principle is the same: you’re a consumer of a commodity input with uncertain future pricing, and you’d prefer to pay a premium for certainty rather than face tail risk in your procurement budget.
Exposure #3: Residual value
When you’re done with these GPUs—whether through normal refresh cycles, strategic pivots, or liquidity needs—their secondary market value becomes relevant.
The range is wide. A robust secondary market might pay $15,000 per unit. If the architecture becomes obsolete for training and less attractive for inference, values could fall to $8,000 or below. Add in factors like export controls affecting buyer pools, and you’ve got significant variance.
You’re short volatility here too: a crash in residual values hurts asymmetrically. For AI-native companies planning sustained high utilization, this matters less—you’re extracting value through use. But for companies with uncertain utilization, or where these assets might need to be liquidated, residual value becomes the exit strategy.
It’s worth noting that lenders understand this dynamic. GPU-backed financing typically involves 40-50% haircuts because lenders recognize the secondary market is thin and subject to volatility. There’s a meaningful gap between balance sheet carrying values and what lenders consider reliable collateral.
Exposure #4: Outside-option pricing (competitiveness vs. market clearing prices)
As GPU-hours increasingly trade as commodities with observable market prices, internal economics become benchmarked against external alternatives.
You might currently value internal compute at $3.50 per GPU-hour based on equivalent cloud rental costs. At 75% utilization, that’s roughly $23,000 per GPU annually in internal value. The capital allocation looks reasonable.
But consider what happens if market prices for delivered compute fall to $2.00 per hour as new generations improve price-performance. Your internal cost basis is now 75% above the outside option. The GPUs still function—but the build-versus-buy decision gets reconsidered.
This isn’t a hedgeable P&L exposure unless you can actually act on the price difference (sell capacity externally, arbitrage the spread, or genuinely substitute cloud for owned capacity). But it’s a competitiveness signal that affects strategic decisions: when do you stop buying and start renting? When do you expand owned capacity versus scaling elastically?
Think of it as basis risk against your outside option. It’s not about hedging—it’s about having instrumentation that tells you when your cost structure has diverged from market reality.
The Structural Tension
Here’s the structural tension: you’re simultaneously long residual value (you own the asset) and short replacement cost (you need future capacity). Plus you’re short volatility on both: spikes and crashes both hurt.
If GPU prices decline, residual values suffer but replacement costs look attractive. If prices rise, residual values strengthen but refresh budgets strain. You can reasonably worry about both scenarios, but managing them would involve different—sometimes opposite—strategies.
This duality is inherent to owning productive assets in rapidly evolving technology markets. The question becomes: Are we in the business of underwriting GPU volatility, or not? That reframes “AI strategy” as a deliberate risk posture rather than just a CapEx line item.
A Simple Model
Let’s move from qualitative to quantitative. Consider a 1,000-GPU fleet purchased at $25,000 per unit—$25 million total investment.
Refresh in 30 months. Next-gen pricing is uncertain:
Base case: $30,000 per equivalent-performance unit (modest inflation)
Optimistic case: $22,000 (supply improves, price-performance gains)
Pessimistic case: $45,000 (supply shock, vendor pricing power)
Residual value at refresh is correlated with next-gen pricing but with jump risk:
If next-gen is cheap, used GPUs trade at $12,000 (40% below current)
If next-gen is expensive, used GPUs retain $18,000 (scarcity value)
But architectural obsolescence could create a step-down: maybe only $8,000 if new models make old architectures uncompetitive
Utilization scenarios dramatically change the picture:
At 90% utilization: $4/GPU-hour → $31,536 per GPU annually in gross value
At 70% utilization: $3/GPU-hour → $18,396 per GPU annually
At 50% utilization: $2.50/GPU-hour → $10,950 per GPU annually
Your depreciation schedule says: $5,000/year per GPU, reaching $12,500 book value at refresh (2.5 years of depreciation).
Your economic reality:
In the optimistic scenario (high utilization, low replacement cost, decent residuals), you’re fine—the project NPV is strongly positive.
In the pessimistic scenario (utilization drops to 50%, next-gen costs $45,000, residuals at $8,000), you face:
$20M replacement cost overrun vs. budget
$7M residual value shortfall vs. book value
Internal cost per GPU-hour now $5+ while market prices are $2
Your smooth depreciation schedule was a point estimate. Your economics are a probability distribution with fat tails in both directions.
This is why “normal CapEx management” isn’t sufficient: GPUs are the first mainstream capital equipment class where normal management quietly implies building a commodity risk function.
Try the model yourself: I’ve built an interactive version of this GPU Risk Simulator in Google Colab. You can adjust the utilization rates and hardware prices to see how the Impairment Cliff affects your specific balance sheet. Launch Interactive GPU Model —>
Why The Obvious Hedge Is Dangerously Imperfect (Basis Risk)
Even if liquid GPU derivatives markets existed, they’d face a fundamental challenge: what exactly is the reference price?
In oil markets, you hedge WTI or Brent crude—well-defined benchmarks with liquid spot and futures markets. Basis risk between your specific crude grade and the benchmark exists but is manageable.
In GPU markets, the basis problem is more severe:
What defines “equivalent” performance? H100 vs. H200 vs. B200? Training throughput? Inference efficiency? Memory bandwidth? Different workloads care about different specs.
Delivered compute varies dramatically by interconnect topology, networking quality, power availability, cooling efficiency, geographic location, software stack optimization, and job type. An H100 in one datacenter isn’t interchangeable with an H100 elsewhere.
Secondary market prices are sparse and model-specific. There’s no daily settlement price for “used H100s” the way there is for crude oil. Pricing is bilateral, negotiated, often confidential.
Utilization and uptime matter but aren’t observable. A “GPU-hour” that’s actually available and productive is different from a GPU-hour with 10% downtime or scheduling inefficiency.
So any standardized index would have significant basis risk relative to your specific fleet. You might hedge H100-equivalent compute only to discover your particular configuration, location, and workload profile doesn’t track the index well.
This doesn’t make hedging impossible—commodity markets deal with basis risk constantly through basis swaps and customized contracts. But it means the “obvious hedge” is more complicated than it first appears, and the market infrastructure required is substantial.
This is probably the main reason GPU derivatives markets remain nascent: the underlying isn’t fungible enough yet for standardized contracts to work smoothly.
Who Might Be Natural Participants (When Markets Develop)
If more developed GPU risk markets emerge, there would be clear natural participants:
Natural shorts (managing depreciation risk):
Cloud providers and GPU lessors managing portfolios across customers face residual value and replacement cost exposure as their business model. They’d be natural hedgers of depreciation risk through puts or buyback arrangements.
Structured finance vehicles—GPU-backed ABS, equipment leasing structures—need to transform volatile residual values into rated cash flows. They’d be significant users of standardized hedging instruments.
Companies with balance sheet constraints where lenders care about collateral values might need hedging even with strong utilization, to manage covenant risk or financing haircuts.
Natural longs (managing procurement risk):
AI-native companies with predictable scaling trajectories care about what next-generation GPUs will cost. They’d be natural buyers of call options or forward contracts on delivered compute capacity to cap procurement risk.
Companies managing large cloud commitments could hedge compute costs through forward contracts even without owning GPUs, similar to how airlines hedge fuel.
Who probably shouldn’t hedge:
AI-native companies with sustained high utilization generating value through use don’t need residual value hedging—secondary market prices are largely irrelevant if you’re not selling.
Companies with genuinely uncertain utilization face a more fundamental question: should you own these assets at all? Variable cost structures might be more appropriate than ownership plus hedging.
Companies with embedded protection through vendor relationships—trade-in credits, buyback guarantees, upgrade programs—already have synthetic hedging without derivative accounting complexity.
The Accounting Reality (Why Smooth Depreciation Is Misleading But Not Wrong)
It’s worth addressing the accounting directly. Depreciation isn’t “wrong”—it’s a systematic allocation method that assumes value declines predictably over useful life. That’s reasonable for many assets.
But for GPUs, economic obsolescence often arrives in jumps rather than linearly. Under US GAAP, this shows up through impairment: when there’s a triggering event (new generation launch, utilization collapse, market price crash), companies test for recoverability. If carrying value exceeds future cash flows, you write down the asset.
The challenge is that impairment is:
Lumpy and lagging (trigger-based, not continuous)
Subject to management discretion about whether triggers exist
Measured through cash flow projections that are easy to rationalize until they’re suddenly not
So what you get is: smooth depreciation plus occasional large write-downs. The P&L sees cliffs, not slopes. Volatility is hidden until it explodes.
This is why many companies will prefer operational and commercial hedges (lease structures, vendor buybacks, flexible offtake agreements) over derivatives. True derivatives introduce ASC 815 complexity and mark-to-market income statement volatility. Embedded commercial terms avoid that while providing similar economic protection.
The Practical Mapping: Exposure → Instrument
If you’re a CFO thinking about managing these risks, here’s what the toolkit might look like:
Utilization variance: Not directly hedgeable. Solutions are operational—leasing, cloud burst capacity, workload portability, splitting fleet into core plus surge, structuring offtake with flexibility.
Replacement cost: Call options or caps on a standardized delivered-compute index (when they exist), or vendor price cap clauses negotiated at procurement. Commercial terms often easier than financial derivatives.
Residual value: Puts or floors via vendor buyback guarantees, residual value insurance from specialty underwriters, or repo-style financing with mark-to-market triggers. Again, commercial terms often dominate financial instruments.
Outside-option pricing: Not hedgeable, but instrumentable. Track your net internal cost per GPU-hour against observable external indices. Use divergence as a policy trigger for build-versus-buy decisions.
Most of this lives in procurement and operations, not treasury. Many “hedges” are embedded derivatives that procurement negotiates, not financial contracts that treasury executes.
Where Things Stand
The puzzle is this: exposures are substantial (order of magnitude: tens of billions per hyperscaler annually, plus many mid-tier players), hedging technology exists in analogous markets, natural counterparties clearly exist—yet market infrastructure remains limited.
This isn’t because CFOs are unsophisticated. It’s because:
The underlying isn’t fungible enough for clean standardization
Basis risk is severe enough to make generic indices problematic
Most early hedging happens through commercial contracts, not financial derivatives
The accounting complexity of derivatives often exceeds the risk reduction benefit
This will likely evolve as absolute dollar amounts continue growing and as compute becomes more commoditized. But the timeline is uncertain.
In the meantime, companies are making large capital commitments in a rapidly evolving technology market, often with less sophisticated risk instrumentation than they’d apply to currency exposure or commodity inputs—not through negligence, but because the frameworks and tools are still being built.
Many GPU investments will generate substantial value where depreciation risk proves immaterial compared to strategic benefits. For others, the gap between accounting treatment and economic reality might eventually matter more than currently anticipated.
The question worth asking: Are you in the business of underwriting GPU volatility? If yes, are you getting compensated for that risk? If no, what’s your plan for managing it?
Understanding which category you’re in—and whether you need to actively manage these exposures or can comfortably absorb them—is increasingly a question worth addressing systematically rather than leaving implicit.
If you enjoy this newsletter, consider sharing it with a colleague.
I’m always happy to receive comments, questions, and pushback. If you want to connect with me directly, you can: