The GPU Debt Treadmill
Why the safest instruments in AI infrastructure finance are hiding the riskiest business model

Neil Tiwari of Magnetar Capital appeared on the podcast No Priors last week to talk about financing the AI compute buildout. Magnetar is a $22 billion alternative asset manager, one of the earliest institutional backers of CoreWeave, and among the most active lenders in the GPU infrastructure space. Neil runs AI infrastructure investments for the firm. He builds some of the financing structures I’ve been analyzing in this newsletter.
The interview is worth listening to in full, but there’s a tension at the center of it that I want to pull apart. Neil makes an airtight case for why the specific debt instruments Magnetar designs are safe. But in doing so, he sidesteps the systemic risks that make the broader ecosystem fragile. These risks sit just outside the walls of his ring-fenced SPVs.
The Case for GPU Debt: Stronger Than You Think
Neil’s core point is that the media narrative around GPU-backed debt is fundamentally wrong. The standard critique goes like this: GPU clouds have taken on billions of dollars in debt collateralized by rapidly depreciating hardware. GPUs, in other words, are like cars. You wouldn’t collateralize debt with cars, and doing so with GPUs is reckless.
Neil dismantles this pretty effectively. The structures Magnetar builds are SPVs containing the capex (the GPUs), the contracts, and the cash flows. The primary collateral is take-or-pay contracts from investment-grade counterparties: companies with credit ratings strong enough to make their contractual commitments essentially bankable. Think Microsoft, Meta, Nvidia, and similar companies. These companies sign five-year commitments with the neocloud. The debt fully amortizes over the contract term. There’s no balloon payment. By the time the debt matures, the balance is zero.
In this analysis, GPU depreciation is genuinely irrelevant to the lender. You don’t care what an H100 is worth in 2028 if Microsoft has already paid off your note through contracted cash flows by then. The residual value of the hardware, whatever it is, accrues to the equity holder. The lender is made whole.
This is well-designed infrastructure credit. Full stop. If you’re a pension fund or insurance company looking at this paper, Neil’s pitch is sound.
The Strawman and the Real Risk
Neil spends considerable time debunking the depreciation critique, but that framing was always secondary to the more fundamental question. The “used car” analogy got traction because the space was new and the numbers were large, but it pointed at the wrong risk.
The right question is about chip obsolescence, not as a collateral risk to current lenders, but as a structural risk to the business model that needs to keep raising new debt tranches.
Neil himself sets this up beautifully, almost accidentally. He cites1 Semi Analysis data showing Blackwell chips could be 90-100x more efficient than Hopper for inference workloads, not 30x, as Nvidia initially claimed.
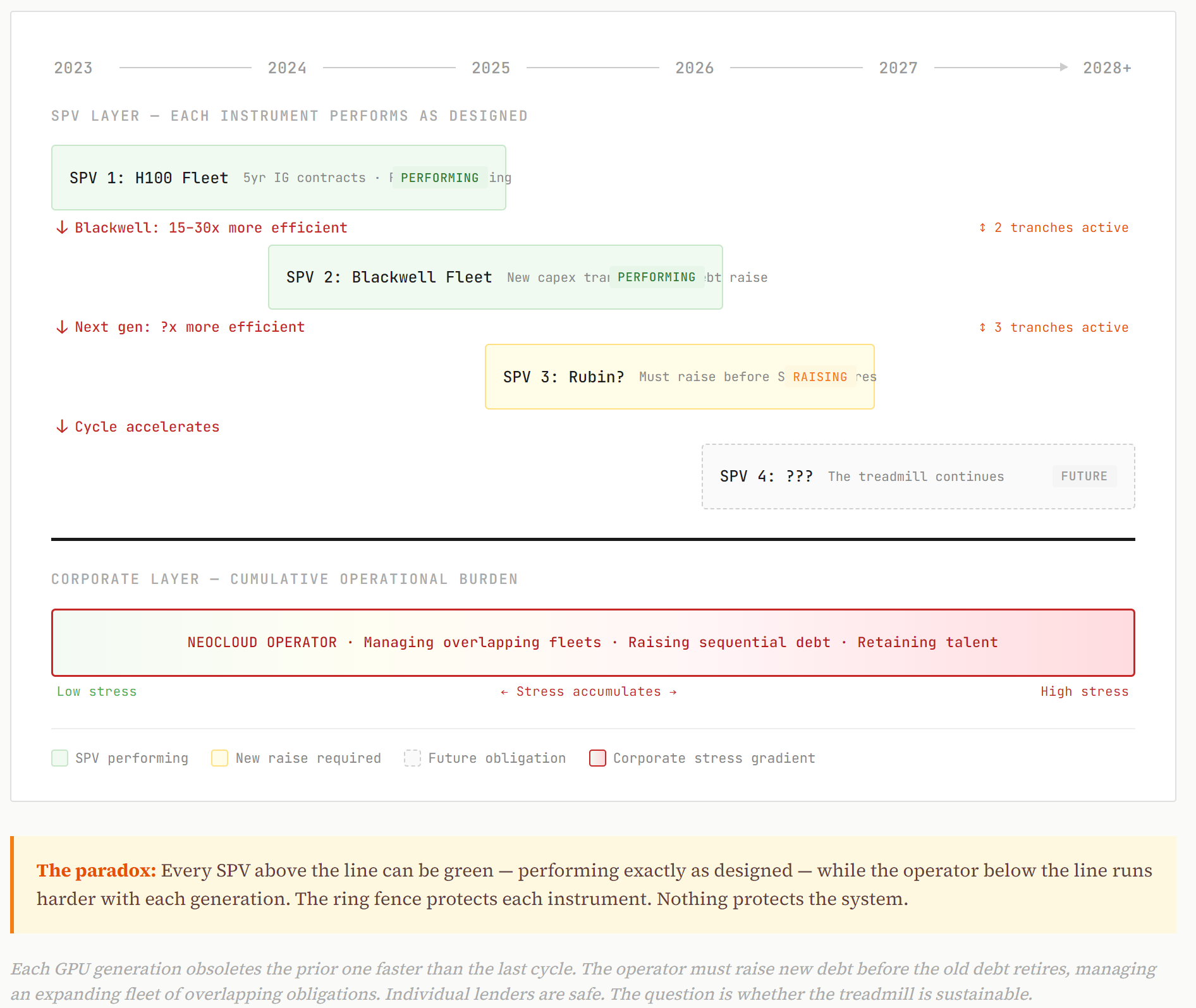
So here’s the dynamic: CoreWeave (or any neocloud) takes on debt to buy H100s backed by 5-year IG contracts. The debt amortizes. The lender is fine. But by year 3, those H100s are being lapped by hardware that is an order of magnitude or more efficient for the workloads where margins are best. To stay competitive, the operator needs to raise a new capex tranche for the next generation. And another after that. Each generation obsoletes the last one faster than the prior cycle did.
This is the treadmill. And the treadmill is an equity problem until it isn’t.
When the Equity Problem Becomes a Credit Problem
Neil’s disciplined answer to all of this is implicit: I’m a lender. I’m senior to equity. I don’t care about the equity story. And instrument by instrument, that’s correct. But a neocloud operator is an operating company with corporate obligations, a talent base, a customer support apparatus. If the equity story deteriorates, the corporate entity faces stress that can affect its ability to service or manage existing obligations, even if the specific SPV structures are performing.
The lender on tranche one is fine. The question is whether the operator can sustain the treadmill across tranches two, three, and four. Each tranche finances a new GPU generation that obsoletes the last one faster than the prior cycle did. If the treadmill breaks, it won’t break at the SPV level. It’ll break at the corporate level. And that’s where the lender’s ring fence gets tested.
What Magnetar Actually Told Us
Neil Tiwari is a sharp, disciplined credit investor doing exactly what he should be doing. Magnetar’s GPU debt structures are well-designed for what they are. The contracted IG cash flows, the full amortization, the SPV ring-fencing: this is real infrastructure finance craftsmanship. If I were allocating to this paper, the instrument-level pitch would satisfy me.
But instrument-level analysis doesn’t capture systemic dynamics. Each SPV can be performing exactly as designed while the operator underneath is running harder and harder just to stay in place. The structures Neil describes are built to withstand the risks they were designed for. The question is whether the risks that matter most are the ones that were designed for, or the ones that sit just outside the ring fence.
The assumptions underneath GPU infrastructure debt are: that demand for compute remains insatiable, that each hardware generation can earn its returns before the next one makes it obsolete, and that the equity treadmill sustaining the operators doesn’t break. Those assumptions may hold. But they’re assumptions, not certainties. And the speed at which this technology is moving, with generational efficiency gains measured in multiples, not percentages, means the margin for error is thinner than in any prior infrastructure buildout.
Magnetar is building the instruments. Somebody needs to be watching the system.
If you enjoy this newsletter, consider sharing it with a colleague.
I’m always happy to receive comments, questions, and pushback. If you want to connect with me directly, you can:
follow me on Twitter,
connect with me on LinkedIn, or
send an email to dave [at] davefriedman dot co. (Not .com!)
I am not certain, but it seems like Neil is referencing this Semi Analysis piece. According to the piece, the headline number that Neil cites reflects rack-level comparisons (GB300 NVL72 vs H100) with full software optimizations enabled; per-GPU gains are more conservative but still generational, in the 15-30x range depending on workload. Either way, the point stands: that’s a technology generation rendering the prior one uneconomic for the highest-value workloads within 2-3 years.