Closed Source vs Open Source AI: A Cage Fight Few People Understand
The capability spread between closed source and open source AI is only part of the story; the monetizable spread matters as much, and no one is paying attention to it

I’ve been pondering a simple question: if open source models are reaching parity with OpenAI and Anthropic, where are those companies’ moats? Their equity looks overpriced if they’re simply utilities.
The standard pushback is predictable: enterprise agreements, safety certifications, distribution, research talent, regulatory positioning. These are all reasonable explanations, but none are satisfying.
The entire debate keeps circling back to the capability spread, which is the raw performance delta between the best closed model and the best open model on any given benchmark. That number has been compressing for two years. But it’s the wrong number. The number that actually matters for valuations is one nobody has named yet. I’m calling it the monetizable spread: the subset of that capability delta that someone will actually pay a premium for.
The monetizable spread is declining faster than the capability spread. And that divergence is the story the market hasn’t priced.
A Brief History of Compression
The capability gap between open and closed models has followed a trajectory that should alarm anyone holding equity in a frontier lab.
At the end of 2023, the best closed model scored roughly 88% on MMLU–the standard knowledge benchmark–while the best open model managed about 70.5%. By early 2026, that gap is effectively zero on knowledge benchmarks and single digits on most reasoning tasks.
The time dimension is more telling. Epoch AI found that open weight models now trail the state-of-the-art by roughly three months on average. In late 2024, the Epoch team measured that lag at closer to a year.
DeepSeek demonstrated the mechanism. Its V3 base model used 2.6 million GPU hours versus Llama 3 405B’s 30.8 million, an order of magnitude improvement in training efficiency. The R1 reasoning model built on top of it matched OpenAI’s o1 at roughly 3% of the cost.
The capability spread hasn’t gone to zero. Frontier models still lead on the hardest tasks, such as complex agentic coding, multi-step tool chaining, and long-horizon workflows where reliability matters as much as raw intelligence. But the list of tasks where they meaningfully lead is getting shorter every quarter. And that distinction, between leading on benchmarks and leading on tasks people pay for, is everything.
The Monetizable Spread
The diagram tells the story.
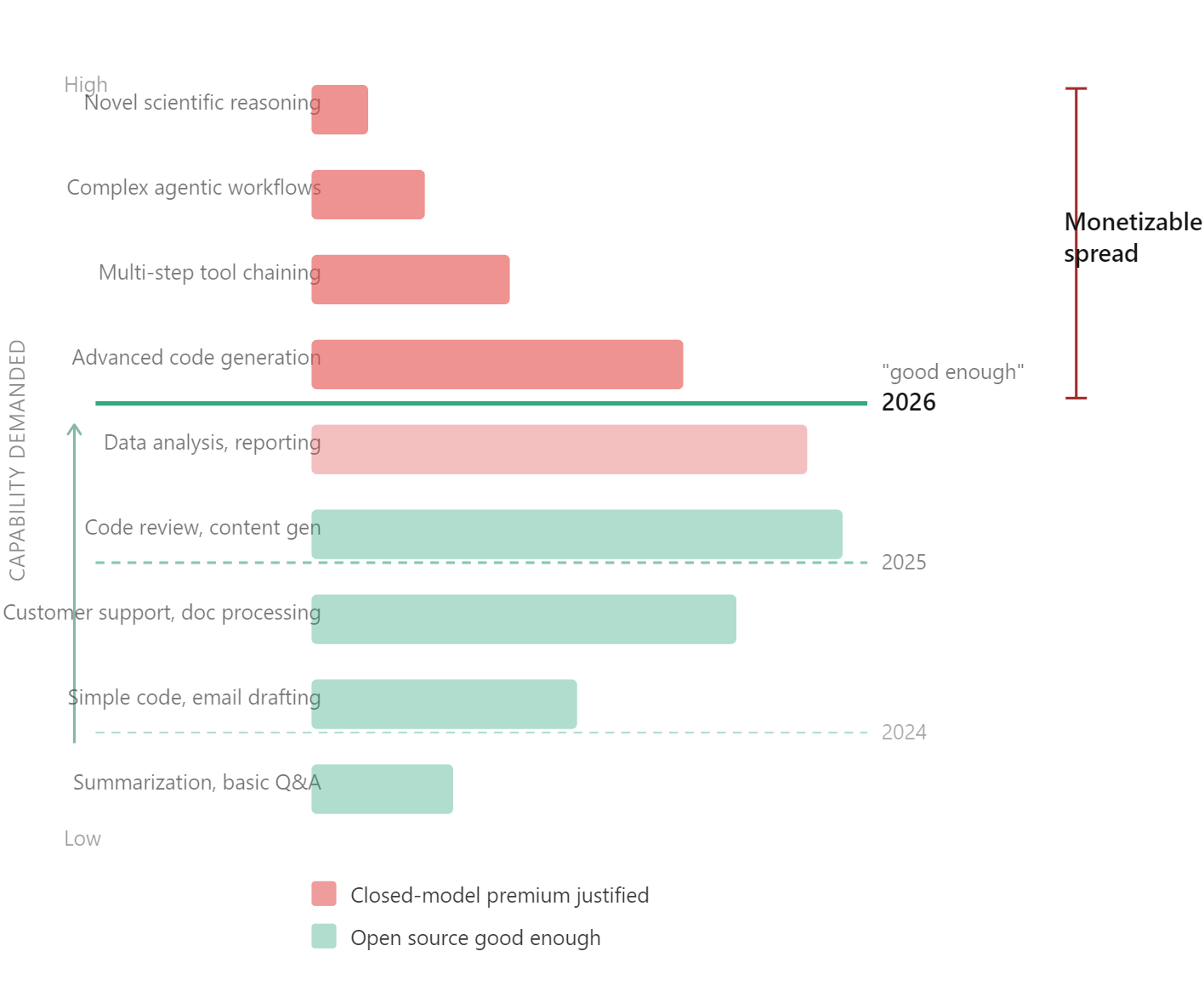
Stack all AI use cases by much capability they demand. At the bottom you have simpler tasks like summarization, basic Q&A, and translation. Open models solved these over a year ago. At the top of the stack, you have more demanding tasks, and here, frontier models still win. In between sits the massive middle band where most of the revenue lives.
The “good enough” line is the threshold where open models become functionally interchangeable with closed ones for a given use case. It moves up every quarter. Each time it does, a slice of paying customers loses their economic justification for the closed model premium.
That’s the monetizable spread: the gap between the “good enough” line and the top of the stack, multiplied by the revenue density at each layer.
It’s important to understand the assumptions baked into my argument. Nobody has published a clean dataset mapping AI revenue by task complexity. The revenue density at each tier is an assertion, not a measurement. But the proxy data is strongly directional. Anthropic’s own Economic Index shows that computer and mathematical tasks, including routine coding, account for 36% of API usage, with the rest distributed across writing, research, education, and other knowledge work that doesn’t require frontier capability. Menlo Ventures’ enterprise survey found that code completion and productivity tools, not agentic systems, drove the category’s breakout spending. Deloitte’s 2026 enterprise AI report found that 37% of organizations are using AI at a “surface level” with little process change, another 30% are redesigning key processes, and only 34% are doing the kind of deep transformation where frontier models genuinely matter. The fat part of the revenue distribution is overwhelmingly mundane work. Drafting, summarization, code assistance, document processing. The stuff where “good enough” arrived a year ago.
The capability spread can hold steady or even widen at the frontier. But if the “good enough” line keeps rising into the fat part of the revenue distribution, the monetizable spread compresses anyway. Fixed-income people will recognize the dynamic: credit spread compression where the underlying risk hasn’t changed, but the bid for yield has pushed capital down the quality spectrum. The technical spread between investment grade and high yield persists in basis points. The economic significance of that spread–the marginal dollar it moves–compresses as everyone crowds into the carry trade. Same thing here. The capability spread persists. The monetizable spread doesn’t care.
What the Valuations are Actually Pricing
Open AI is seeking $100 billion in funding at an $850 billion valuation. Internal projections show $14 billion in losses for 2026 alone, with cumulative losses of $115 billion through 2029 before profitability arrives, possibly in the 2030s. Revenue is growing fast, at an annualized run rate of around $25 billion, but at $850 billion you’re paying north of 30x revenue on a company with a 33% gross margin constrained by inference expenses. And OpenAI is paying Microsoft 20% of total revenue through 2032, a structural drag that most people ignore.
Anthropic closed a $30 billion Series G round at a $380 billion valuation in February, more than doubling its prior valuation in under six months. Run-rate revenue hit $14 billion, with Claude Code alone at $2.5 billion. That implies roughly 27x price-to-sales. Anthropic anticipates positive free cash flow in 2027, a faster path than OpenAI, but still a bet on durable pricing power.
These valuations are pricing two different stories.
OpenAI at $850 billion is a distribution bet. ChatGPT has 900 million weekly active users and over 50 million consumer subscribers. That’s a consumer attention asset, not a model capability asset. The model could fully commoditize and that user base retains value, the same way Google’s search algorithm isn’t what makes Google valuable anymore. If you believe OpenAI pivots from model provider to platform, the valuation has a certain logic. But it’s an execution bet, not a technology bet, and ChatGPT’s web traffic share has already fallen from 86.7% to 64.5% in twelve months as Gemini and others take share. Distribution moats look less durable when the product is a text box.
Anthropic at $380 billion is a purer model layer bet. Roughly 80% of its revenue comes from enterprise. But this is precisely the revenue most exposed to monetizable spread compression, because enterprise buyers are exactly the people who run the “is the premium worth it for this workload” calculation every quarter. They have procurement teams. They build multi-model architectures. They will switch.
Where the Value Migrates
If the model layer margin compresses, value flows to two places.
Down to infrastructure. The people financing, operating, and trading the compute itself. GPU-backed lending, compute derivatives, data center financing. The margins here are structurally different from model layer margins because compute is a physical asset with real collateral value, not a software product competing with free alternatives. Nvidia sits here. So does the emerging compute financialization ecosystem: the exchanges, lenders, and people building derivatives markets around GPU capacity.
Up to applications. Whoever builds the dominant AI-native workflows on top of commodity intelligence. The application layer captures value precisely because the model layer doesn’t: cheap, interchangeable intelligence becomes the substrate for differentiated products, the way cheap cloud compute enabled SaaS. The winners here haven’t been identified yet, which is part of the point.
The Timeline Problem
When does monetizable spread compression become a valuation crisis?
Anthropic says it will be free cash flow positive in 2027, and profitable in 2028. OpenAI’s projections push profitability into the 2030s. Both timelines assume pricing power that the “good enough” line is actively eroding.
Run it forward. The open source lag has compressed from twelve months to three months in two years. LLM inference costs are dropping roughly 10x annually. If these trends hold, and nothing in the data suggests they won’t, then by 2028, when Anthropic needs to demonstrate profitability and OpenAI needs to IPO into a public market that demands real margins, the “good enough” line will have climbed through the majority of today’s revenue-generating use cases. The top of the stack will still exist. The question is whether the revenue up there can support these multiples. The hardest tasks are, almost by definition, the thinnest market.
Unless–and this is the escape hatch–the frontier labs invent entirely new categories of high-value work at the top faster than open source commoditizes the middle. That’s possible. It’s also the bet you’re making at 2-30x revenue on a 33% gross margin business. You’re paying for the option on a future that may not arrive before the present catches up.
Where This Thesis Breaks
There are three vulnerabilities which ought to be mentioned, because this piece is useless if it doesn’t survive contact with smart pushback.
First: What if frontier models keep creating new high value user cases at the top faster than open source eats the middle? This is the iPhone objection. Apple didn’t defend the premium tier of the phone market. It invented new tiers that didn’t exist. If agentic AI creates entirely new categories of work that only frontier models can handle, the top of the stck gets fatter even as the middle gets eaten. The “good enough” line moves up, but the revenue above it expands, too. This is the strongest counter to the thesis, and I don’t have a clean answer for it. What I’d say is: so far, every new capability that’s appeared at the frontier, including coding, reasoning, and multi-step planning, has been reproduced by open models within months, usually at a fraction of the cost. The iPhone analogy requires the frontier labs to produce something that stays proprietary, and the evidence so far is that nothing does. But “so far” doing a lot of work in that sentence.
Second: both companies are moving up the stack into products. Claude Code at $2.5 billion ARR isn’t API revenue. It’s a product with its own UX, workflow integration, and switching costs. If these products succeed, these companies are capturing value at the application layer while owning the model layer. The risk to my thesis is that model layer margins compress but product layer margins compensate. The risk to their thesis is that products built on proprietary models face competition from products built on open models with no inference margin to defend, and history suggests the cheaper substrate wins.
Third: regulation. If AI regulation tightens, being the established, responsible provider with government relationships becomes a genuine structural advantage. (This is in part why Anthropic’s reaction to the Department of Defense’s designation of it as a supply chain risk has been so vigorous.) Anthropic has positioned itself deliberately for this world. First-mover advantages in safety compliance don’t commoditize the way model performance does. But this is a political bet, not a technology bet, and political bets have a way of not paying off on the timeline investors need.
The Bottom Line
The capability spread is a benchmark story. The monetizable spread is a valuation story. Revenue growth on a narrowing moat is a different asset than revenue growth on a widening one. The market is pricing the latter. The monetizable spread says it’s buying the former.
If you enjoy this newsletter, consider sharing it with a colleague.
I’m always happy to receive comments, questions, and pushback. If you want to connect with me directly, you can:
Excellent analysis; I like how these articles focus on topics and questions in the AI space that rarely arise in mainstream discussions, and with a level of intellectual thoroughness that it is almost never seen.
There are substantial economies of scale in serving ai though, open source or closed. We should expect the largest ai companies to also have the best margins on open source tokens. So regardless, the big gpu owners win, which at this point includes anthropic and OpenAI. But more importantly this analysis does not give enough credit to the data flywheel (Google is “just a text box” as well after all) and the vast economic space that lies above current model capabilities still — all of knowledge work, as a start (40% of gdp). Can open source keep up as the training data shifts from public internet tokens to complex proprietary knowledge workflows?